calculate_metrics_by_thresh_binary (y_true:<built-infunctionarray>,
y_prob:<built-infunctionarray>, metri
cs:Union[Callable,Sequence[Callable]]
, thresholds:Optional[Sequence]=None)
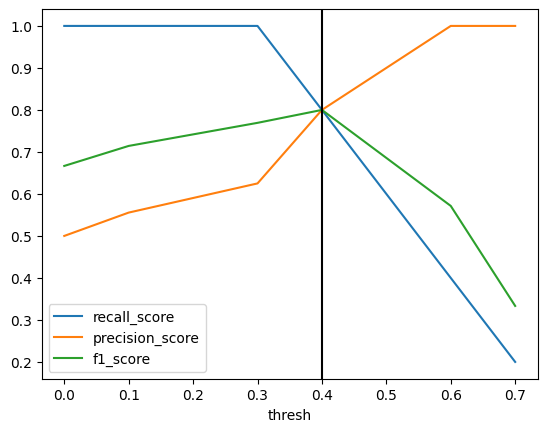
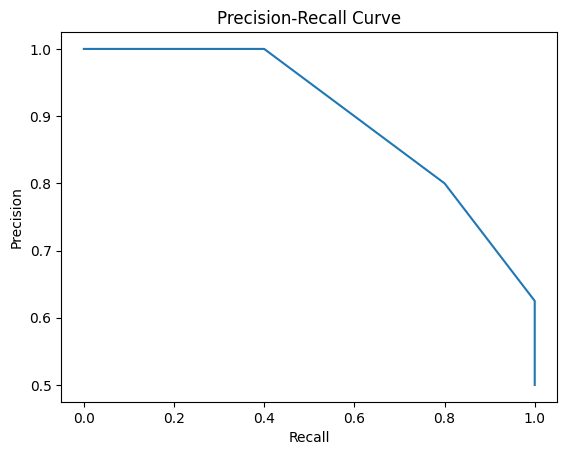
Calculate binary classification metrics as a function of threshold
Takes prediction to be 1 when y_prob is greater than the threshold, 0 otherwise.
Parameters:
y_true: Ground-truth values with shape (n_items,)
y_prob: Probability distributions with shape (n_items, 2)
metrics: Callables that take y_true, y_pred as positional arguments and return a number. Must have a __name__ attribute.
thresholds: Sequence of float threshold values to use. By default uses 0 and the values that appear in y_prob[:, 1], which is a minimal set that covers all of the relevant possibilities. One reason to override that default would be to save time with a large dataset.
Returns: DataFrame with one column “thresh” indicating the thresholds used and an additional column for each input metric giving the value of that metric at that threshold.
0%| | 0/7 [00:00<?, ?it/s]/Users/greg/.pyenv/versions/model_inspector/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1344: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 due to no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
100%|██████████| 7/7 [00:00<00:00, 472.74it/s]
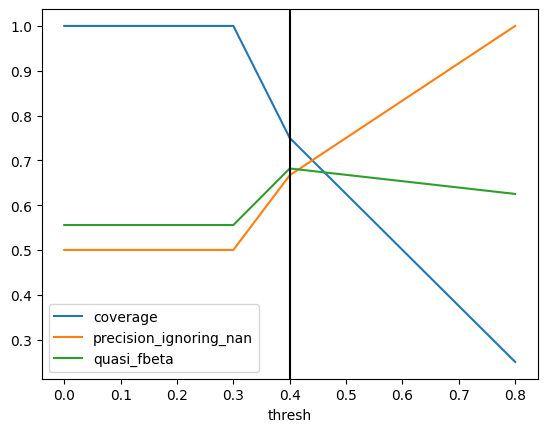
Calculate multiclass metrics as a function of threshold
Takes prediction to be the position of the column in y_prob with the greatest value if that value is greater than the threshold, np.nan otherwise.
Parameters:
y_true: Ground-truth values
y_prob: Probability distributions
metrics: Callables that take y_true, y_pred as positional arguments and return a number. Must have a __name__ attribute.
thresholds: Sequence of float threshold values to use. By default uses 0 and all values that appear in y_prob, which is a minimal set that covers all of the relevant possibilities. One reason to override that default would be to save time with a large dataset.
Returns: DataFrame with one column “thresh” indicating the thresholds used and an additional column for each input metric giving the value of that metric at that threshold.
Suppose that in a multiclass problem we want to track two metrics: coverage (how often we make a prediction) and precision (how often our predictions are right when we make them). We will choose the threshold an \(F_\beta\)-like metric that maximizes a weighted harmonic mean of those two metrics that puts twice as much weight on precision as coverage.
0%| | 0/8 [00:00<?, ?it/s]/Users/greg/.pyenv/versions/model_inspector/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1344: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 due to no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
100%|██████████| 8/8 [00:00<00:00, 582.12it/s]